图像融合与处理中心负责人石宣化教授,通过详细的实验分析解释 TensorFlow和 PyTorch 在单 GPU上训练性能差异的根本原因,从而为用户在这两个框架之间选择时提供指导。
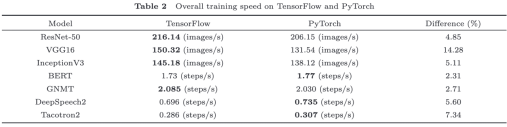
表 TensorFlow和PyTorch在不同模型上的训练速度差异
该研究提出以下五个主要结论:(1)大部分模型的训练时间主要是GPU计算时间,这表明核心kernel的实现在GPU训练中起着至关重要的作用。(2)卷积层有许多不同的实现算法,更快的算法通常需要更多的内存。当模型很大或训练批量很大时,TensorFlow 是比 PyTorch 更好的选择。(3)最好的卷积算法需要在运行时profile所有可用的算法。(4)从业者应该在可能的情况下尽可能使用更优化的 LSTM 实现(如cuDNNLSTM),kernel实现人员应该在实现高性能的同时提供更灵活的 API。(5)图优化在大多数神经网络中对训练速度的影响基本可以忽略掉,用户无需因为单GPU下训练速度的考虑而在TensorFlow和PyTorch间犹豫如何选择。该研究成果发表在《中国科学》上。

